
Document Summarization Techniques Using Large Language Models
From Simple Prompts to Sophisticated Workflows
ARTIFICIAL-INTELLIGENCE
codetechdevx
8/16/20253 min read
Document Summarization Techniques Using Large Language Models: From Simple Prompts to Sophisticated Workflows
The explosion of digital content has created an unprecedented need for effective document summarization. From research papers and legal documents to customer feedback and news articles, organizations are drowning in textual data that requires quick analysis and understanding. Large Language Models (LLMs) have emerged as powerful tools for automated summarization, but their effective implementation requires understanding various techniques and their optimal applications.
The Evolution of Automated Summarization
Traditional summarization approaches relied on rule-based systems and statistical methods that could identify key sentences but often missed contextual nuances. Modern LLMs have revolutionized this landscape by understanding context, maintaining coherence, and generating human-like summaries that capture the essence of complex documents.
However, the power of LLMs comes with unique challenges. Prompts for large language models are usually token-count-limited, meaning that simply feeding entire long documents into an LLM often isn't feasible. This limitation has driven the development of sophisticated techniques for handling documents that exceed model context windows.
Core Summarization Approaches with LLMs
Direct Summarization for Short Documents
For documents that fit within an LLM's context window, direct summarization remains the simplest and most effective approach. This involves crafting a well-structured prompt that clearly specifies the desired summary characteristics:
Length requirements (word count or percentage of original)
Focus areas (key findings, recommendations, technical details)
Audience considerations (executive summary vs. technical brief)
Format preferences (bullet points, paragraphs, structured sections)
The key to successful direct summarization lies in prompt engineering. Effective prompts provide clear instructions, examples of desired output, and specific constraints that guide the model toward producing useful summaries.
Map-Reduce Summarization for Long Documents
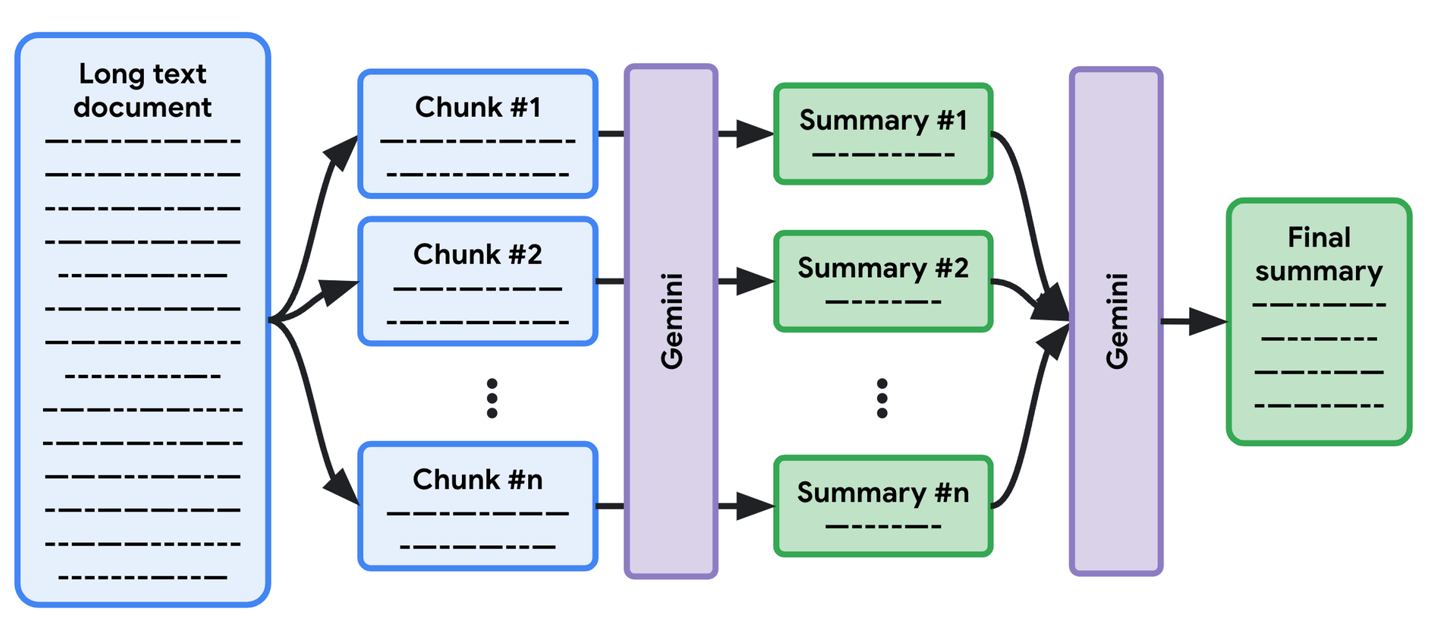
With map/reduce, you can create a summary for each section in parallel (the "map" operation), with a final summarization in the last step (the "reduce" operation). This approach has become fundamental for processing documents that exceed LLM context windows.
The Map-Reduce method involves several stages:
Document Segmentation: The original document is divided into chunks that fit comfortably within the LLM's context window. This segmentation must preserve semantic coherence, ideally breaking at natural boundaries like paragraphs, sections, or chapters.
Parallel Processing (Map Phase): Each document chunk is processed independently to generate individual summaries. This parallelization significantly reduces processing time compared to sequential approaches.
Aggregation (Reduce Phase): All chunk summaries are combined and processed through a final summarization step to create a cohesive overview of the entire document.
This technique scales efficiently and maintains quality across documents of various lengths. The parallel processing capability makes it particularly attractive for enterprise applications where processing speed matters.
Iterative Refinement Summarization
The iterative refinement approach takes a different strategy, where a summary is created for the first section, then the LLM refines its first summary with the details from the following section, and iteratively through to the end of the document.
This sequential method offers several advantages:
Contextual Continuity: Each refinement step has access to the running summary, allowing for better integration of information across document sections.
Adaptive Emphasis: As new sections are processed, the model can adjust the emphasis of the summary based on emerging themes or important information.
Quality Control: Each iteration provides an opportunity to maintain consistency and coherence in the evolving summary.
However, the sequential nature means longer processing times for large documents, making it less suitable for time-sensitive applications.
Advanced Summarization Techniques
Hierarchical Summarization
For extremely long documents or document collections, hierarchical summarization creates multiple levels of abstraction. This approach might involve:
Creating summaries of individual sections
Grouping related sections and summarizing the groups
Producing chapter-level summaries
Generating an overall document summary
This technique is particularly valuable for complex documents like research reports, legal cases, or technical manuals where different levels of detail serve different audiences.
Query-Focused Summarization
Rather than creating generic summaries, query-focused approaches generate summaries tailored to specific information needs. Users can specify questions or topics of interest, and the LLM produces summaries that emphasize relevant information while de-emphasizing less pertinent content.
This technique is especially valuable in scenarios like:
Legal document review focusing on specific clauses or issues
Research paper analysis targeting particular methodologies or findings
Business report summarization emphasizing financial implications
Multi-Modal Summarization
Modern LLMs increasingly handle documents containing text, images, tables, and charts. Multi-modal summarization techniques can:
Extract key information from embedded charts and graphs
Describe important visual elements
Integrate textual and visual information into coherent summaries
Maintain references to visual elements in the summary
Location
Bangalore, India
Karnataka
Copyright
© 2025 CodeTechDevX
All rights reserved