
Exploring projects that bridge legacy systems with modern AI
From Concept,
to Code

Text to Image generation
Text-to-image is a fascinating area of artificial intelligence that creates a visual image from a text description, or "prompt." The core idea is that we describe what we want to see, and the AI generates it for us. This technology is built on large-scale models that have been trained on billions of images and their corresponding text descriptions. The model learns to associate words and phrases with visual patterns, colors, styles, and compositions.
At a high level, the process generally works like this:
Prompt Interpretation: The AI first processes our text prompt (e.g., "a cat wearing a spacesuit, digital art") and translates it into a numerical format that the model can understand.
Image Generation: The model then begins to generate the image, often starting from a random field of noise and gradually refining it. It uses our prompt as a guide to "denoise" the image, adding the features we described until a complete picture emerges.
Result: The final output is an image that visually represents the text we provided.
Explanation of Playground-v2.5-1024px-aesthetic
The model we are using, playgroundai/playground-v2.5-1024px-aesthetic, is a specialized text-to-image model built on this foundation. Here's a breakdown of what that name means and how it works:
playgroundai: This is the creator or the company behind the model. Playground AI is known for its focus on creating high-quality generative models.
playground-v2.5: This is the specific version of the model. The "v2.5" indicates that it is an updated and improved version of a previous model, likely with better performance, finer control, and higher-quality outputs.
1024px-aesthetic: This part gives you crucial information about the model's capabilities and design.
1024px: This specifies the optimal output resolution. The model is fine-tuned to produce images that are 1024x1024 pixels, which is a high-resolution size that captures a great amount of detail.
aesthetic: This is a key differentiator. The model has been specifically trained on a dataset of images that are considered visually pleasing and high-quality. This means that, by default, the model is biased toward generating beautiful, stylized, and artistic images rather than photorealistic or generic ones. It has an inherent understanding of what makes an image "good" from a design and composition perspective.
In summary, when we use this model, we are interacting with a sophisticated AI that is not only generating an image from our words, but is also specifically trained to produce visually stunning, high-quality art at a high resolution (1024x1024 pixels). This makes it particularly effective for creative projects where the final aesthetic is a priority.
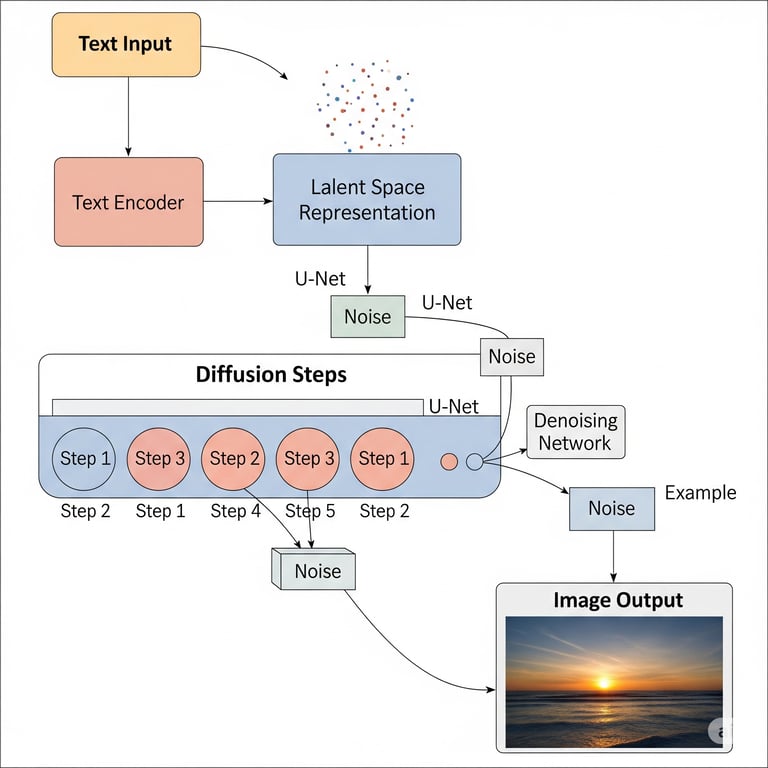
1. Text Input
The process starts with your Text Input (the yellow box). This is the text prompt you provide, such as "a cat in a spacesuit." The model can't work directly with these words, so it needs to convert them into a language it understands.
2. Text Encoder
The Text Encoder (the red box) takes your text prompt and translates it into a numerical representation. This is a complex process where the model figures out the meaning and context of your words, converting them into a code or vector that captures their semantic information.
3. Latent Space Representation
The output of the text encoder is a Latent Space Representation (the blue box). This is like a highly compressed, abstract blueprint of your image. Instead of being an actual picture, it's a grid of numbers that contains all the key information about the desired image, such as color, style, and content, in a much smaller size. Think of it as a detailed set of instructions for building the final image.
4. Noise
The process begins with Noise. The AI starts with a completely random, static-like image, much like the static you'd see on an old TV. The goal of the next steps is to remove this noise.
5. Diffusion Steps
This is the core of the magic. The Diffusion Steps (the large blue box with circles) refer to a series of iterative refinements. The model uses a Denoising Network (often a U-Net architecture) to gradually clean up the random noise. In each step, the model looks at the noisy image and, guided by the latent space representation (your text prompt), removes a small amount of noise. This process is repeated many times, with the image becoming clearer and more defined with each step.
6. Image Output
After all the diffusion steps are complete, the final, denoised image is ready. The Image Output (the final box) is the finished product—the visual representation of your original text prompt. It's the end result of the model turning a string of text into a detailed picture.
Location
Bangalore, India
Karnataka
Copyright
© 2025 CodeTechDevX
All rights reserved